
October 2020, Vol. 247, No. 10
Features
Support for DRA-Treated Liquid Pipelines Using No-Code Digital Twins
By Craig Harclerode, Senior Systems Engineer, and Andrew Nathan, Principal, OSIsoft
Midstream oil and gas operators own large distributed pipeline networks that transport natural gas, crude oil, refined products and other hydrocarbon liquids to refineries, storage and markets.
However, this fluid transport is hampered by frictional pressure loss coupled with elevation head losses, which, in some cases, lead to capacity constraints. To counter this, liquid pipeline operators use drag reducing agents (DRAs) to mitigate the frictional pressure loss and achieve the required liquid head. Roughly three-quarters of the crude oil and refined products flowing through U.S. pipelines are DRA-treated.1
The challenge for liquid pipeline operators is to balance DRA selection, effectiveness and costs against the benefits of reduced pumping energy requirements and the ability to increase pipeline capacity while maintaining the same energy use.
The capability to do this analysis for DRA-treated pipelines and act in near real-time – versus an offline weekly or monthly reactive approach – is essential for responding rapidly to operational and market fluctuations and optimizing the net benefits.
Extracting actionable insights and optimizing DRA-treated pipeline performance is challenging due to the large and diverse amount of operational, meta and financial data from disparate sources: SCADA systems and other sensors, pipeline hydraulic and scheduling software, enterprise resource planning (ERP) platforms, computerized maintenance management systems (CMMS), and many others. Examples of such types of data include:
- Pump performance curves
- Pump, driver and pipeline segment sensor data such as temperature, flow, pressure, vibration and amp
- DRA efficacy data with different liquids such as crudes or refined products
- Batch data with associated amount, type and location of the liquid within the pipeline
- Financial information associated with pipeline capacity and energy costs from multiple sources
- Pipeline elevation and geospatial data
An operational data infrastructure2 is a key foundational tool to enable the creation of a real-time decision support platform for DRA-treated pipelines, turning these disparate data sources into actionable operational intelligence.
This digital infrastructure empowers hydraulics, scheduling, rotating equipment and pipeline integrity subject matter experts (SMEs) to configure, evolve and manage their DRA decision support application directly using the data infrastructure2 with “no-code” digital twins.3 This is in contrast to the more traditional approach of developing or purchasing a customized digital solution for DRA management with significant IT involvement and associated customization.
Another key capability with this digital infrastructure is the integration of the DRA, energy and capacity application with other pipeline real-time decision support requirements. These include the following:
- Management dashboards with key performance indicators (KPIs) and exception-based operational intelligence
- Real-time pipeline and pump asset performance intelligence, including analytics and roll-ups
- Asset anomaly detection with alerts, event tracking and exception-based notifications
- Condition-based maintenance with maintenance management system integration
In short, the DRA, energy and capacity application should not be a standalone solution, but rather a part of a comprehensive pipeline operational decision support system leveraging the same foundational information.
This article presents the use of a real-time operational data infrastructure2 for DRA-treated pipeline monitoring and highlights associated dashboards and decision support displays used by SMEs, managers and other stakeholders.
The article also focuses on SME-configurable “no-code” operational digital twins3 and summarizes best practices in the development and use of the operational data infrastructure and no-code digital twins.
Real-time Decision
The DRA, energy and capacity management application is based on an integrated, hierarchical set of dashboards that enables self-serve and contextualized access to operational intelligence, and it delivers “one version of the truth” using a modern, web-enabled visualization platform.
As a best practice, the smart dashboard should have a rolled-up summary of all pipeline system information, including integration with geospatial, safety and environmental information, with the ability to drill down through the portfolio of smart displays. The smart displays should leverage exception-based, conditional formatting to communicate equipment status efficiently and effectively.
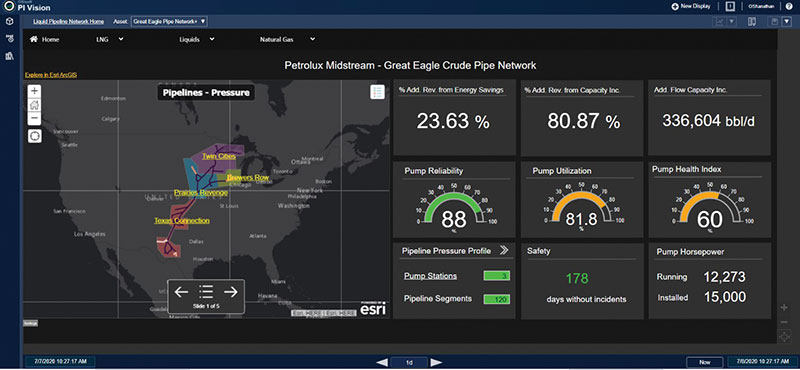
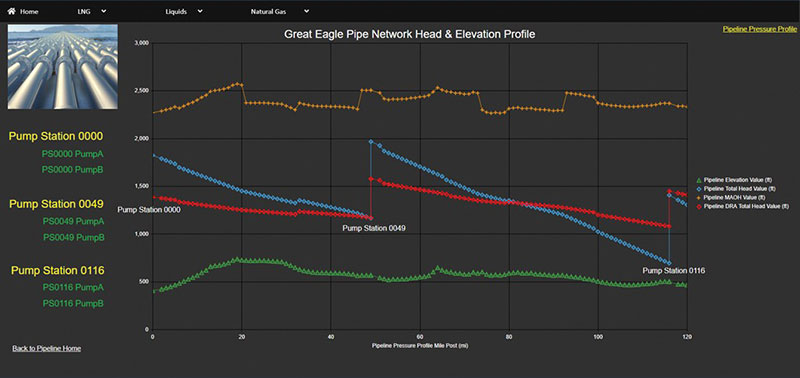
Figure 1 is an example of a smart display developed for a hypothetical midstream company with a 120-mile (193-km) long liquid pipeline comprising 120 pipe segments, three pump stations and six pumps. This smart display was configured by dragging and dropping desired asset and pipeline attributes from a pipeline asset hierarchy onto a smart display canvas. Since there is no programming or coding required, end users can configure and customize their own smart displays or rely on standard, enterprise-level smart displays.
This display also has a conditionally formatted geospatial Esri map layered with real-time information such as pipe segment pressures versus maximum allowable operating pressures (MAOP). By selecting a region on the map, further drill-down details and intelligence can be accessed.
Addionionally, the summary dashboard has equipment rollup KPIs such as overall system pump reliability, utilization and a health index, which are configured and managed by the rotating equipment SMEs.
The dashboard also showcases financial KPIs such as percent revenue increases from energy savings and capacity increase. Other information such as safety days can be linked from associated data sources.
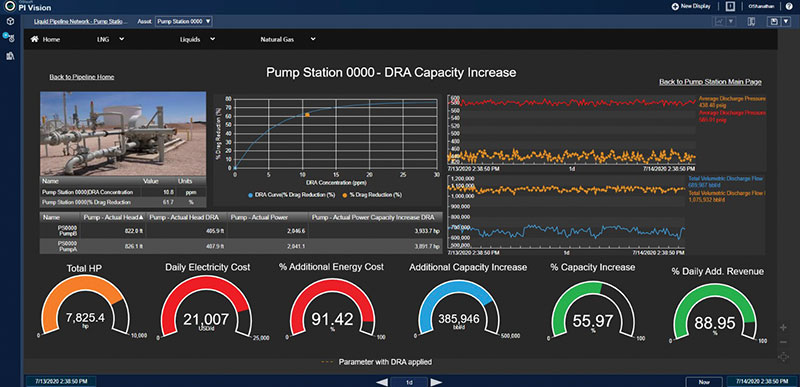
Another smart display (Figure 2) drills down from the summary dashboard into one of the three pump stations in a capacity increase DRA scenario. Since this display is referencing a pump station that uses an underlying no-code digital twin template,3 the user can easily configure this dashboard for one pump station and then reuse it for the other two pump stations without modification. This capability significantly reduces smart display creation and management workloads.
This display provides pump station-specific KPIs, current operating trends as well as deltas from baseline operations. DRA efficacy can be quantified by overlaying historical as well as real-time DRA concentrations on the DRA performance curve to correlate DRA injection levels with tracked KPIs and trends.
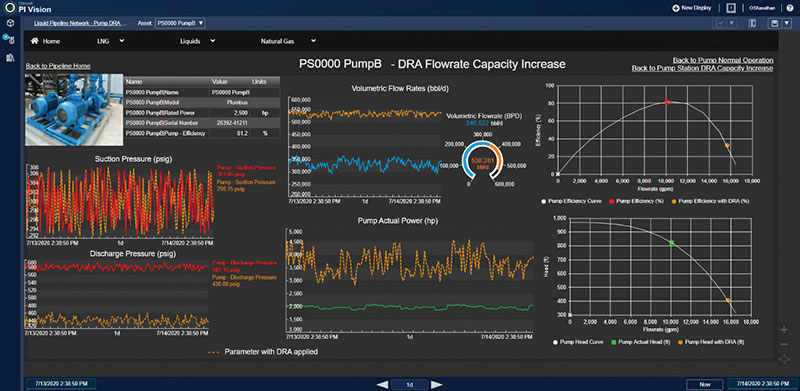
For more granularity, it’s easy to drill down to the individual pump smart display (Figure 3). As with the pump station display, the underlying use of asset templates enables this smart display to be used across all pumps in the pipeline system via context switching.
The detailed display shows pump performance data, trends as well as current operating efficiency and head along the manufacturer pump curves. Forecast or future data can also be trended together with historical and real-time information, enabling comparison with model-based predictions.
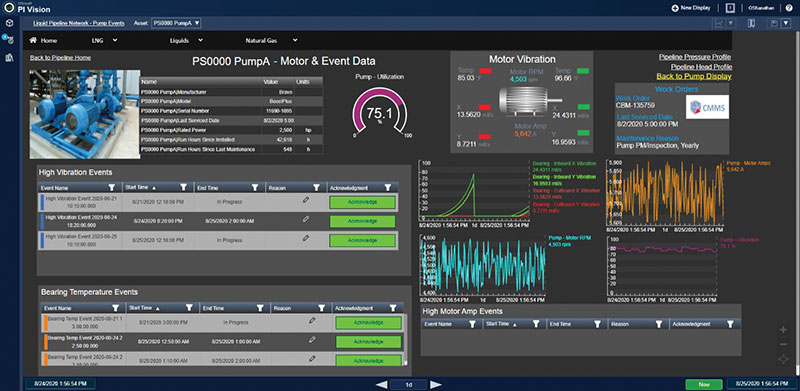
Pump motor vibration, downtime events and maintenance system integration can also be visualized in a separate display. Equipment excursion periods such as high vibration and bearing temperature events can be automatically created by defining rule-based start and end event analytics.
Another powerful capability is “backcasting” these event analytics (or any expression) on historical data to enable insight into when the defined event occurred in the past. These events can automatically trigger notifications to relevant parties or workflows to external systems such as work order creation in a CMMS.
A way to visually evaluate DRA effectiveness in near real time is to plot on a nomograph the DRA-treated pipeline head and pressure profiles against the non-DRA scenario obtained from hydraulic simulation and modeling tools.
Using different DRA types and amounts, an SME can immediately evaluate the impact of DRA on the liquid pipeline over different time periods to determine optimal DRA injection moving forward. Once decided, the DRA injection operating procedures can be adjusted with real-time monitoring of the actual versus projected values with economic impact totaled over time.
The real-time operational infrastructure2 is an agnostic, open, scalable and reliable technology specifically designed for critical operations with capabilities and functionality that enable:
- Integration of all operational data and asset metadata sources using both tag-based interfaces and asset-based connectors
- Gross error detection and data validation using rules and expressions
- Historization and rapid retrieval of high-fidelity operational data, including the ability to store future data for forecasting
- Data integration from remote and mobile assets, some of which can go “dark” due to inconsistent connectivity
- Standardization and abstraction of diverse tag and asset naming into a consistent naming lexicon using human-readable names
- Governed access to different contextual views of the asset hierarchy and asset-level details
- Normalization of units of measure and time zones, including the ability to cast into different measurement units
- An analytical foundation for performing descriptive, diagnostic, simple, predictive analytics that acts as a foundation for more advanced analytical methods such as advanced pattern recognition and machine learning
- SMEs to configure and manage assets via no-code operational digital twin templates
- Configuration of common applications such as energy management, asset performance management and condition-based maintenance (CBM).
Digital Twins
A digital twin is a replica of a physical asset such as a pump or a compressor comprising attributes, calculations, KPIs, empirical correlations and models of varying complexity. Contrary to the current hype, digital twins have been around since the 1960s. However, today’s operationally focused digital twins are dramatically more robust and sophisticated in their ease of use, approach and capability to develop, evolve and leverage in a digital pipeline system.
Most digital twins require IT, data scientists, machine learning, model integration and coding. They also have a limited ability to deal with volume, velocity, variability and anomalies. They are difficult to scale and struggle to address the anomalies of physical assets that have variability in vintage, makes, models and levels of instrumentation.
Furthermore, real-time operational data and asset metadata (i.e., static information like equipment model and location) typically reside as tags in control systems, as well as in other databases and platforms, with accessibility issues and lack of naming standards limiting access to critical data that could potentially be leveraged to gain insights.
However, one operations-focused digital twin technology3 has access to the aforementioned required data with the ability for the SMEs to configure replicas of their digital pipeline system components such as drivers, pumps, pump stations, meters and pipeline segments in an agile, evolutionary way.
These no-code digital twins rely on digital asset templates and can be combined like LEGO blocks to form a comprehensive digital representation of a physical liquid pipeline system using drag-and-drop capabilities.
Another key capability of the no-code digital twin is the integration of pump and DRA performance curves in addition to common descriptive, diagnostic and simple predictive analytics around pump operations, including events such as a pump-driver anomaly or failure. This is accomplished by enabling the SME to create or modify calculations, then test the hypothesis by backcasting, i.e., running the expression back into the operational history.
Once satisfied with the expression, the SME can then forward-cast this modified expression or event detection algorithm to other assets that utilize the same digital twin template. This powerful capability enables continuous improvement of calculations, expressions and event analytics over time as well as comparison of similar expression results, KPIs or events as part of the diagnostic process.
A real-world data infrastructure with no-code digital twin technology now operates across DCP Midstream, one of the largest midstream operators in North America. DCP Midstream has natural gas, natural gas liquid (NGL) and other liquid pipelines and thousands of associated drivers, pumps and compressors.
DCP’s engineers have configured more than 400 no-code digital twin templates in an evolutionary, agile method that have been combined to form an operational digital twin of their entire enterprise, with over 11,000 digital twin instances.
The specific application of this no-code digital twin capability can be used to configure attribute categories such as:
- Metadata from a maintenance management system such as make, model, location, last maintenance date and spare parts information
- Fluid properties obtained from a table or database identifying the current liquid being moved
- Real-time operating data such as suction and discharge pressures/temperatures
- Analytics and calculations for pump run hours, efficiency, horsepower, etc.
- Forecast data/future predictions such as volumetric flowrate forecasts
- Costing and financial data such as electricity costs that could vary by time of day, source and pump station
- Associated informational links to items such as piping and instrumentation diagrams (P&IDs), standard operating procedures, specific web pages or work process documentation
These no-code digital templates can also be configured to perform a range of anomaly detections and event tracking, and provide alerts and notifications. To address the variances in equipment types, makes and vintages, these digital twin templates need to contain sub-templates or derived templates to capture these deviations from the base template.
In the templates, the attributes are placeholders for the actual, asset-specific values that are mapped once when the template is applied to an actual asset.
‘Layers of Analytics’
Terms such as advanced analytics, machine learning, big data and artificial intelligence (AI) appear pervasively in marketing literature today, but it can lead to confusion, failed projects and significant lost opportunity costs.
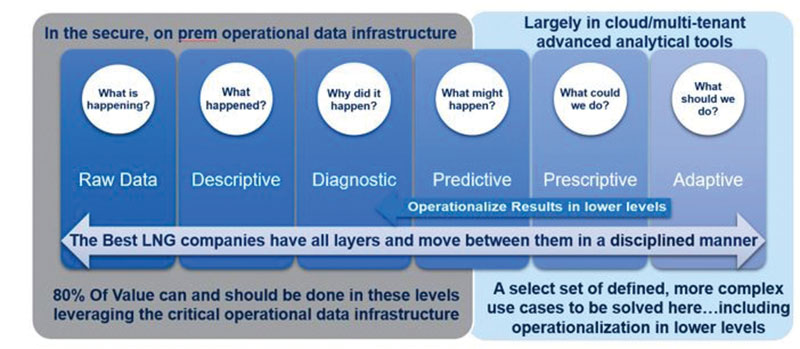
The most successful pipeline operators achieve value from analytics by first defining an analytics framework and types of analytics required and then selecting fit-for-purpose technologies. They use a “layers of analytics” strategy, which considers incremental cost vs. incremental value as they move to more complex analytical methods. The costs include not only the technology, but costs associated with lost time to value, scalability, configuration and sustainment.
The foundation of this “layers of analytics” approach (Figure 5) relies on the use of an operational data infrastructure to enable SMEs, not IT, to configure real-time descriptive, diagnostic and simple predictive analytics using formulas, empirical correlations and rule-based expressions. These lower-level analytics form the foundation for more advanced predictive, prescriptive and adaptive analytics that use machine learning and other methods and require collaborative support from data science teams.
These foundational analytical layers generally provide more than 80% of the value for about 20% of the cost versus more advanced analytical layers that only use technologies such as machine learning. Once higher layers of analytics are used, it is imperative to feed back the results of these advanced layers to the lower-level layers as forecasts or targets to operationalize the advanced analytical output.
Conclusion
Pipeline operators are facing numerous operational and market challenges. Leading companies will continue to aggressively adopt digital technologies that enable agility, flexibility, operational excellence and proactive decision support to optimize DRA, energy and capacity applications and other liquid pipeline operations.
Adopting an operational data infrastructure with no-code operational digital twins based on a “layer of analytics” strategy, as well as building smart dashboards, are the keys to a successful digital transformation. The enablement of SMEs to develop, configure and evolve these no-code digital twins with minimal IT support is the secret to the digital pipeline of the 21st century.
Notes
- Carr, H. Kind of a Drag: Boosting Crude and Products Pipeline Capacity with Drag Reducing Agents. RBN Energy LLC.
- OSIsoft’s PI System functions as a real-time operational data infrastructure for critical operations and enables SMEs to configure no-code digital twins to create self-serve access to contextualized operational intelligence and to support a layer of analytics strategy.
- No-code digital twins refer to the PI System’s Asset Framework (AF) that includes an integration, abstraction and contextualization layer via data references to other data sources; a portfolio of 110 analytical functions optimized for time-series data that leverage a wizard capability for ease of use; event framing that enables configurable event start and end times with event analytics; and a configurable notification engine to trigger alerts via SMS, emails or work orders in a maintenance management system.
- Hill, Joe. DCP Update on the Use of the PI System. PI World Conference, March, 2019. San Francisco, Calif.
Authors: Andrew Nathan is a senior systems engineer and the midstream oil and gas industry champion at OSIsoft. He has 12 years of experience in the oil and gas industry, specifically data infrastructure with the PI System, analytics, visualization, process engineering, plant and pipeline modeling, operator training, 3-D visualization and virtual environments. He holds a Ph.D. in polymer science from the University of Akron and a bachelor’s degree in chemical engineering from Michigan State University.
Craig Harclerode is a Global O&G and HPI Industry principal at OSIsoft, where he consults with companies on how the PI System can add value to their organizations as a strategic operational real-time integration, applications and analytics infrastructure. He has a 40-year career that includes work in engineering, operations and automation in supervisory, executive management and consultative roles. He holds a bachelor’s degree in chemical engineering from Texas A&M University and a master’s in business administration from Rice University.

Comments